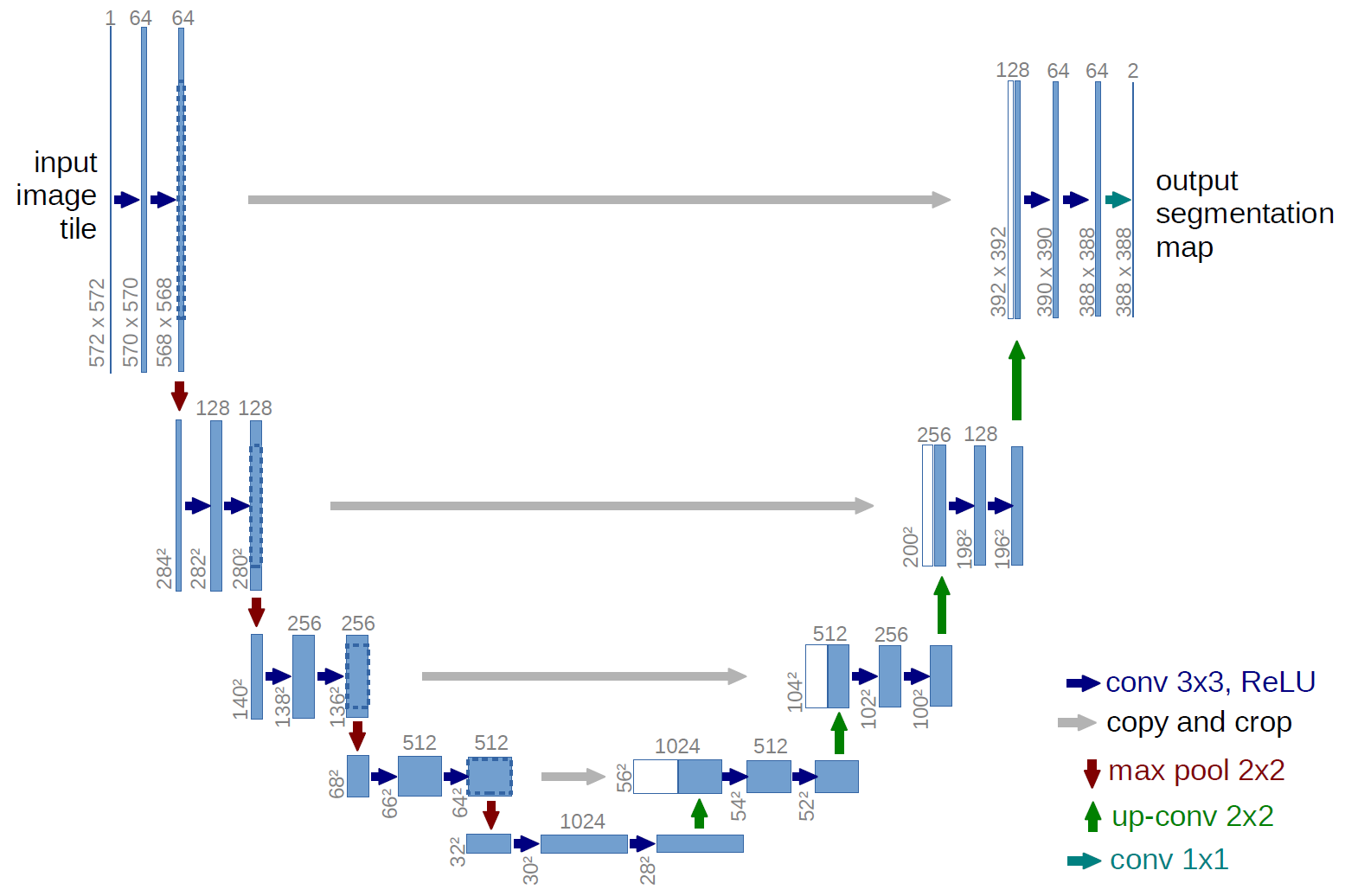
1. shape
简表:
名称
nn.输入参数
输入shape
输出shape
激活函数 Relu\
*
*
展平层 Flatten[start_dim=1, end_dim=-1]
[batch_size, *]
[batch_size, ∏ ∗ \prod * ∏ ∗
线性层 Linearin_features, out_features
[*, in_features]
[*, out_features]
互相关 Conv2din_channels, out_channels, kernel_size
[N N N h h h
[N N N h o u t h_{out} h o u t w o u t w_{out} w o u t
汇聚层 Pool2dkernel_size
[N N N C C C h h h w w w
[N N N C C C h o u t h_{out} h o u t w o u t w_{out} w o u t
归一化 BatchNorm2dchannels
[N N N C C C H H H W W W
[N N N C C C H H H W W W
表的一些约定 :
对于一个名称,如果存在多个对应链接,一般取最常用的那个。
维度变量的表示:一般输入维度都是[batch_size, channels, height, width],偶尔使用in_前缀来区分前后的维度名称,也会使用[N N N C C C H H H W W W N N N C C C h h h w w w
符号:*代表代表任意数量的维度,输入参数里的[]用于表示可选参数。
计算:限于表格大小,公式在上文给出,表格内只给出大致流程。
还没填到表里的:深度可分离卷积、膨胀卷积
2. 激活函数
3. 损失函数
一般使用L L L ℓ \ell ℓ
CrossEntropyLoss L = − ln e x t a r g e t ∑ c ∈ C e x c L = -\text{ln} \frac {e^{x_{target}}} {\sum_{c \in C} e^{x_c}} L = − ln ∑ c ∈ C e x c e x t a r g e t ℓ ( x , y ) = L = { l 1 , … , l N } ⊤ , l n = − w y n log exp ( x n , y n ) ∑ c = 1 C exp ( x n , c ) ⋅ 1 { y n ≠ ignore index } \ell(x,y)=L=\{l_1,\ldots,l_N\}^\top,\quad l_n=-w_{y_n}\log\frac{\exp(x_{n,y_n})}{\sum_{c=1}^C\exp(x_{n,c})}\cdot1\{y_n\neq\text{ignore}_\text{index}\} ℓ ( x , y ) = L = { l 1 , … , l N } ⊤ , l n = − w y n log ∑ c = 1 C exp ( x n , c ) exp ( x n , y n ) ⋅ 1 { y n = ignore index }
y = torch. LongTensor( [ 0 ] )
z = torch. Tensor( [ [ 0.2 , 0.1 , - 0.1 ] ] )
criterion = torch. nn. CrossEntropyLoss( )
loss = criterion( z, y)
print ( loss)
p = torch. exp( z[ 0 , y] ) / torch. sum ( torch. exp( z[ 0 ] ) )
loss = - math. log( p. item( ) )
print ( loss)
4. 优化器
5. 正则化
6. 批标准化
7. 经典网络
7.1 AlexNet
7.2 VGG
7.3 GoogLeNet
7.4 ResNet
7.5 DenseNet
7.6 SENet
7.7 UNet
8. 深度学习模型
8.1. MLP
Multi-Layer Perceptron多层感知机
8.2. CNN
Convolutional Neural Network卷积神经网络
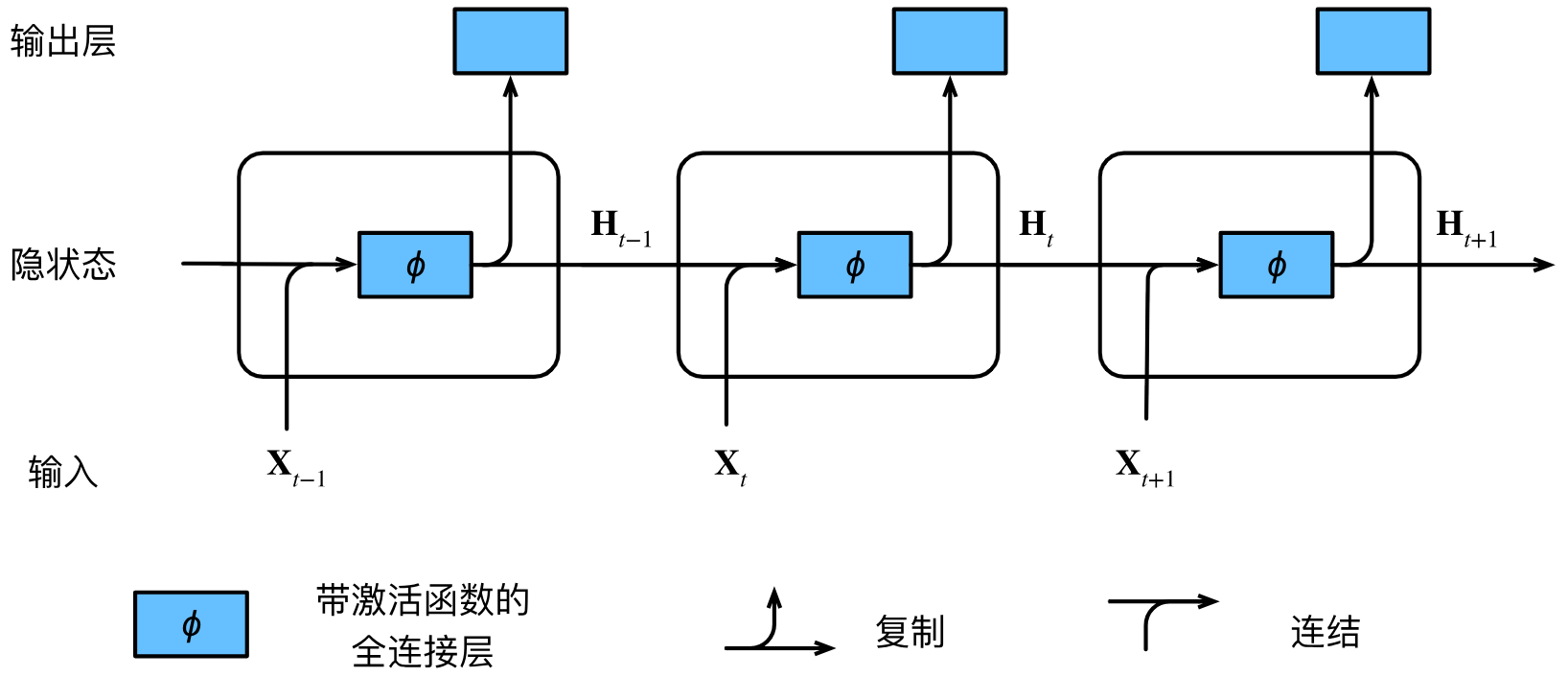
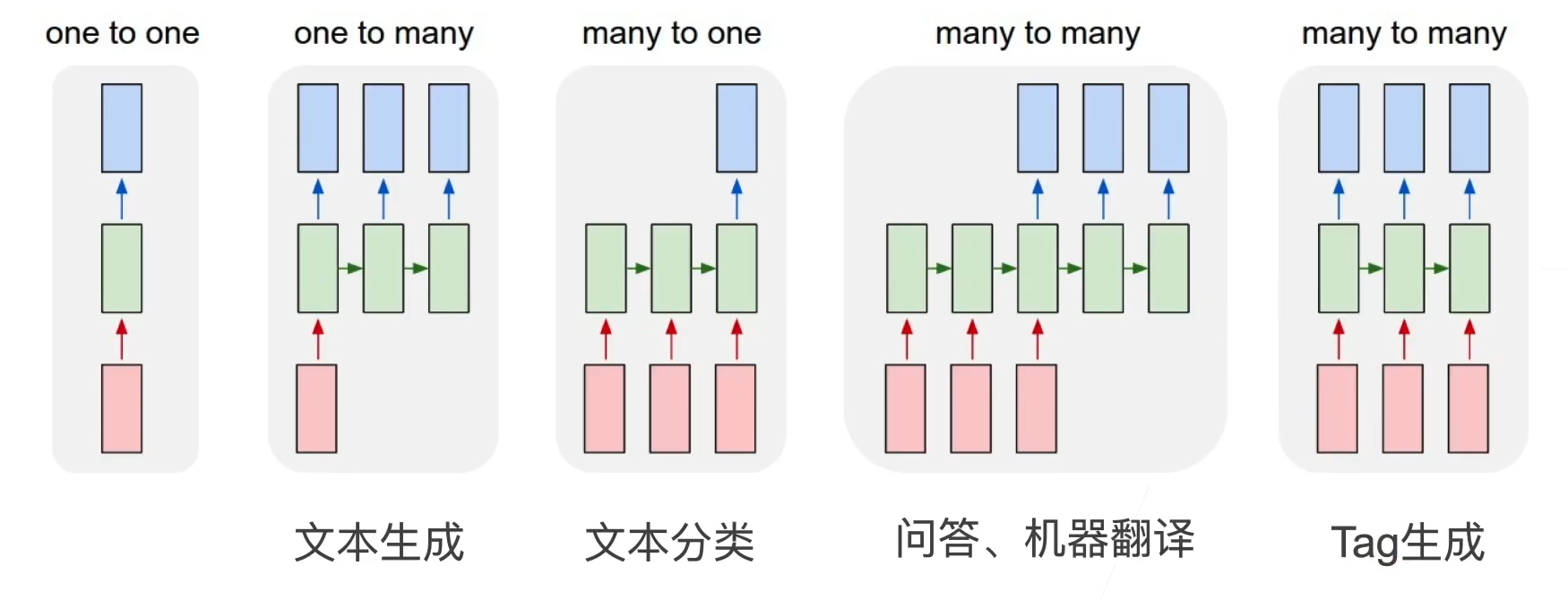
8.3. RNN
Recurrent Neural Network循环神经网络
1. 基本的RNN
之前都是默认数据来自于某种分布,并且所有样本都是独立同分布的。序列信息需要RNN来处理。n n n P ( x t ∣ x t − 1 , . . . , x 1 ) P(x_t\left|x_{t-1},...,x_1\right) P ( x t ∣ x t − 1 , ... , x 1 ) ∣ V ∣ \left|V\right| ∣ V ∣ ∣ V ∣ n \left|V\right|^n ∣ V ∣ n P ( x t ∣ x t − 1 , … , x 1 ) ≈ P ( x t ∣ h t − 1 ) P(x_t\left|x_{t-1},\ldots,x_1\right)\approx P(x_t\left|h_{t-1}\right) P ( x t ∣ x t − 1 , … , x 1 ) ≈ P ( x t ∣ h t − 1 ) h t = f ( x t , h t − 1 ) h_t=f(x_t,h_{t-1}) h t = f ( x t , h t − 1 ) H t ∈ R n × h H_t \in\mathbb{R}^{n\times h} H t ∈ R n × h H t = ϕ ( X t W x h + H t − 1 W h h + b h ) {H}_t=\phi({X}_t{W}_{xh}+{H}_{t-1}{W}_{hh}+{b}_h) H t = ϕ ( X t W x h + H t − 1 W hh + b h ) D D D h h h n n n t t t X t ∈ R n × D X_t \in\mathbb{R}^{n\times D} X t ∈ R n × D H t ∈ R n × h H_t \in\mathbb{R}^{n\times h} H t ∈ R n × h W x h ∈ R D × h W_{xh} \in\mathbb{R}^{D\times h} W x h ∈ R D × h W h h ∈ R h × h W_{hh} \in\mathbb{R}^{h\times h} W hh ∈ R h × h b h ∈ R 1 × h b_h \in\mathbb{R}^{1\times h} b h ∈ R 1 × h ϕ \phi ϕ W x h , W h h , b h W_{xh},W_{hh},b_h W x h , W hh , b h O t = H t W h q + b q {O}_t={H}_t{W}_{hq}+{b}_q O t = H t W h q + b q O t ∈ R n × q O_t \in\mathbb{R}^{n\times q} O t ∈ R n × q W h q ∈ R h × q W_{hq} \in\mathbb{R}^{h\times q} W h q ∈ R h × q b q ∈ R 1 × q b_q \in\mathbb{R}^{1\times q} b q ∈ R 1 × q W h q , b q W_{hq},b_q W h q , b q
评价语言模型的标准是困惑度 (perplexity),对于一篇长度为n n n W = ( x 1 , x 2 , … , x n ) W=(x_1,x_2,\ldots,x_n) W = ( x 1 , x 2 , … , x n ) perplexity ( W ) = exp ( − 1 n ∑ t = 1 n log P ( x t ∣ x t − 1 , … , x 1 ) ) \text{perplexity}(W)=\exp\left(-\frac1n\sum_{t=1}^n\log P(x_t\mid x_{t-1},\ldots,x_1)\right) perplexity ( W ) = exp ( − n 1 t = 1 ∑ n log P ( x t ∣ x t − 1 , … , x 1 ) ) k k k k k k
RNN的不同变种:
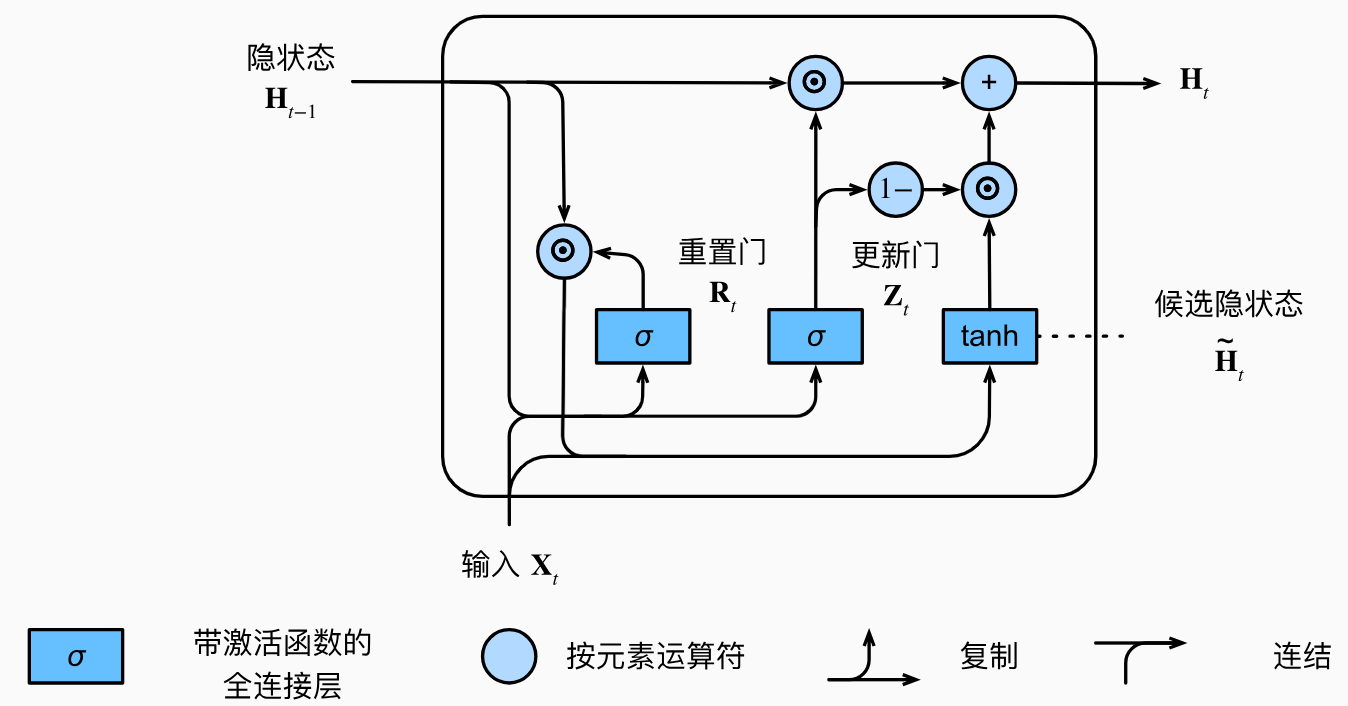
2. GRU
gated recurrent unit门控循环单元
重置门R ∈ R n × h R\in \mathbb{R}^{n\times h} R ∈ R n × h Z ∈ R n × h Z\in \mathbb{R}^{n\times h} Z ∈ R n × h
重置门 reset gate打开时,模型在这个时间步就像一个基本的RNN单元一样,会使用整个隐状态 H t − 1 H_{t-1} H t − 1 短期 依赖关系;更新门 update gate打开时,模型在这个时间步几乎不更新隐状态H t H_t H t 跳过 了这个时间步,有助于捕获序列中的长期 依赖关系。
计算公式如下:R t = σ ( X t W x r + H t − 1 W h r + b r ) ∈ ( 0 , 1 ) Z t = σ ( X t W x z + H t − 1 W h z + b z ) ∈ ( 0 , 1 ) \begin{aligned}
{R}_t&=\sigma({X}_t{W}_{xr}+{H}_{t-1}{W}_{hr}+{b}_r)\in (0,1)\\
{Z}_t&=\sigma({X}_t{W}_{xz}+{H}_{t-1}{W}_{hz}+{b}_z)\in (0,1)\end{aligned} R t Z t = σ ( X t W x r + H t − 1 W h r + b r ) ∈ ( 0 , 1 ) = σ ( X t W x z + H t − 1 W h z + b z ) ∈ ( 0 , 1 ) σ \sigma σ W x r , W h r , b r , W x z , W h z , b z W_{xr},W_{hr},b_r,W_{xz},W_{hz},b_z W x r , W h r , b r , W x z , W h z , b z D × h , h × h , 1 × h D\times h,h\times h,1\times h D × h , h × h , 1 × h H ~ t \tilde{H}_t H ~ t W , b W,b W , b H ~ t ∈ R n × h \tilde{H}_t\in \mathbb{R}^{n\times h} H ~ t ∈ R n × h H ~ t = tanh ( X t W x h + ( R t ⊙ H t − 1 ) W h h + b h ) ∈ ( − 1 , 1 ) \tilde{{H}}_t=\tanh({X}_t{W}_{xh}+({R}_t\odot{H}_{t-1}){W}_{hh}+{b}_h)\in (-1,1) H ~ t = tanh ( X t W x h + ( R t ⊙ H t − 1 ) W hh + b h ) ∈ ( − 1 , 1 ) tanh \tanh tanh ( − 1 , 1 ) (-1,1) ( − 1 , 1 ) R t R_t R t R t R_t R t H t − 1 H_{t-1} H t − 1 H t ∈ R n × h H_t\in \mathbb{R}^{n\times h} H t ∈ R n × h H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t H_t=Z_t\odot{H}_{t-1}+(1-Z_t)\odot\tilde{H}_t H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t Z t Z_t Z t H t H_t H t H t − 1 H_{t-1} H t − 1 Z t Z_t Z t H t H_t H t H ~ t \tilde{H}_t H ~ t
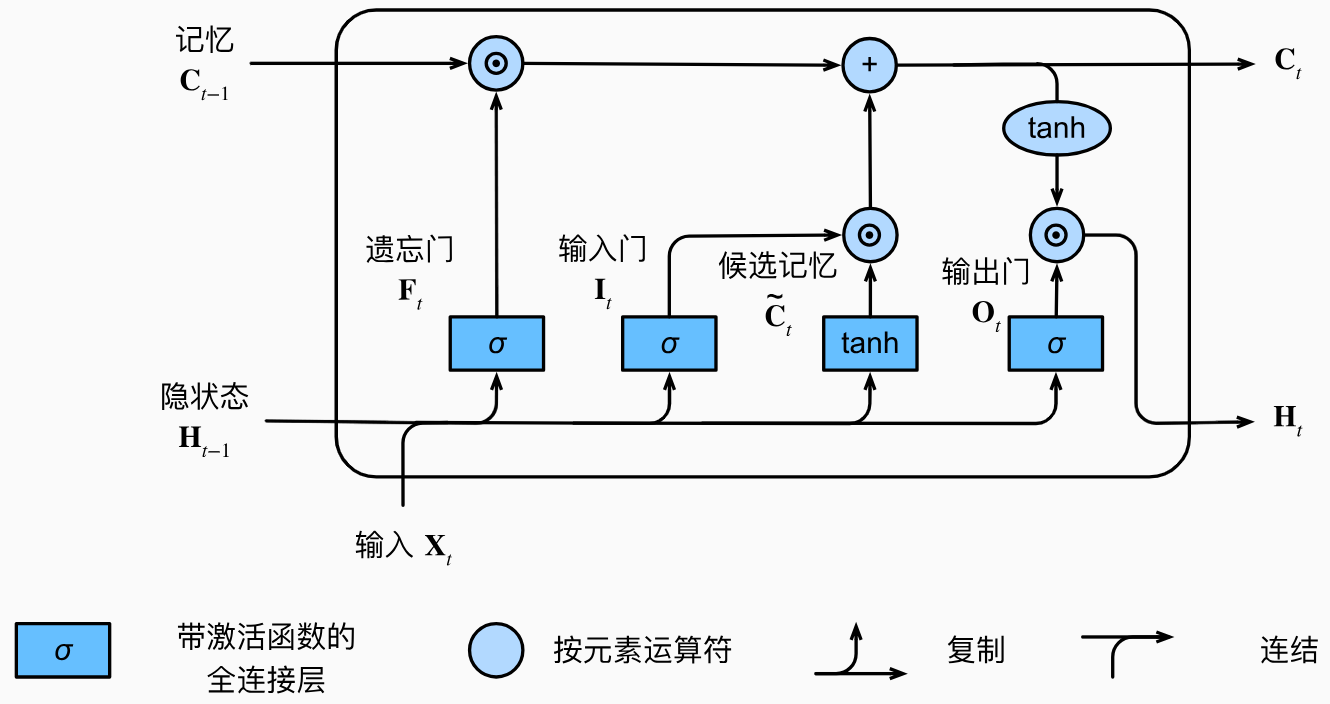
3. LSTM
Long Short-Term Memory长短期记忆
输入门I ∈ R n × h I\in \mathbb{R}^{n\times h} I ∈ R n × h F ∈ R n × h F\in \mathbb{R}^{n\times h} F ∈ R n × h O ∈ R n × h O\in \mathbb{R}^{n\times h} O ∈ R n × h
输入门 input gate打开时,模型允许当前输入X t X_t X t 新的记忆元 C t C_t C t 遗忘门 forget gate打开时,模型保留更多的过去状态信息 C t − 1 C_{t-1} C t − 1 输出门 output gate打开时,模型允许当前记忆元 C t C_t C t H t H_t H t
计算公式如下:I t = σ ( X t W x i + H t − 1 W h i + b i ) ∈ ( 0 , 1 ) F t = σ ( X t W x f + H t − 1 W h f + b f ) ∈ ( 0 , 1 ) O t = σ ( X t W x o + H t − 1 W h o + b o ) ∈ ( 0 , 1 ) \begin{aligned}
{I}_t&=\sigma({X}_t{W}_{xi}+{H}_{t-1}{W}_{hi}+{b}_i)\in (0,1)\\
{F}_t&=\sigma({X}_t{W}_{xf}+{H}_{t-1}{W}_{hf}+{b}_f)\in (0,1)\\
{O}_t&=\sigma({X}_t{W}_{xo}+{H}_{t-1}{W}_{ho}+{b}_o)\in (0,1)\end{aligned} I t F t O t = σ ( X t W x i + H t − 1 W hi + b i ) ∈ ( 0 , 1 ) = σ ( X t W x f + H t − 1 W h f + b f ) ∈ ( 0 , 1 ) = σ ( X t W x o + H t − 1 W h o + b o ) ∈ ( 0 , 1 ) σ \sigma σ W x i , W h i , b i , W x f , W h f , b f , W x o , W h o , b o W_{xi},W_{hi},b_i,W_{xf},W_{hf},b_f,W_{xo},W_{ho},b_o W x i , W hi , b i , W x f , W h f , b f , W x o , W h o , b o D × h , h × h , 1 × h D\times h,h\times h,1\times h D × h , h × h , 1 × h C ~ t \tilde{C}_t C ~ t W , b W,b W , b C ~ t ∈ R n × h \tilde{C}_t\in \mathbb{R}^{n\times h} C ~ t ∈ R n × h C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) \tilde{{C}}_t=\tanh({X}_t{W}_{xc}+{H}_{t-1}{W}_{hc}+{b}_c) C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) tanh \tanh tanh ( − 1 , 1 ) (-1,1) ( − 1 , 1 ) C t ∈ R n × h C_t\in \mathbb{R}^{n\times h} C t ∈ R n × h C t = F t ⊙ C t − 1 + I t ⊙ C ~ t C_t=F_t\odot{C}_{t-1}+I_t\odot\tilde{C}_t C t = F t ⊙ C t − 1 + I t ⊙ C ~ t F t F_t F t C t C_t C t C t − 1 C_{t-1} C t − 1 F t F_t F t C t C_t C t C ~ t \tilde{C}_t C ~ t H t ∈ R n × h H_t\in \mathbb{R}^{n\times h} H t ∈ R n × h H t = O t ⊙ tanh ( C t ) H_t=O_t\odot\tanh(C_t) H t = O t ⊙ tanh ( C t ) O t O_t O t C t C_t C t H t H_t H t
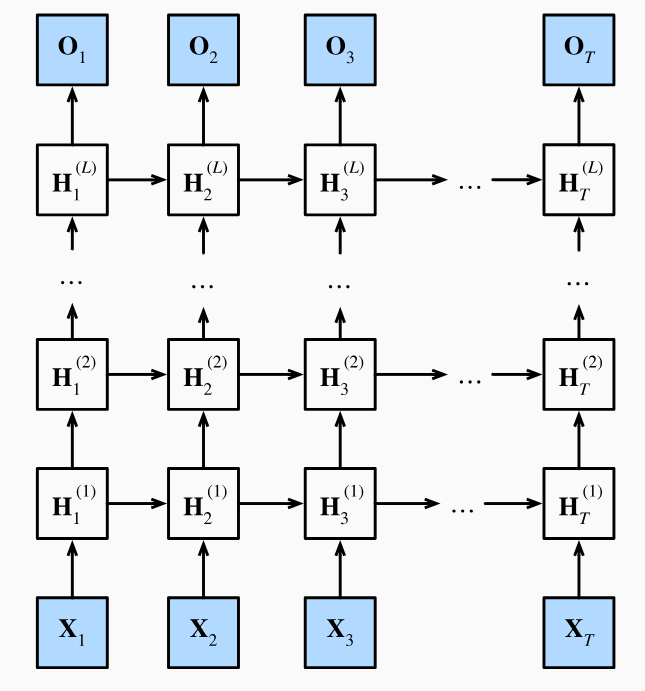
4. 深度循环神经网络
深度循环神经网络的隐藏层输出H t ( l ) ∈ R n × h ( l ) H_t^{(l)}\in\mathbb{R}^{n\times h^{(l)}} H t ( l ) ∈ R n × h ( l ) H t ( l ) = ϕ l ( H t ( l − 1 ) W x h ( l ) + H t − 1 ( l ) W h h ( l ) + b h ( l ) ) {H}_t^{(l)}=\phi_l({H}_t^{(l-1)}{W}_{xh}^{(l)}+{H}_{t-1}^{(l)}{W}_{hh}^{(l)}+{b}_h^{(l)}) H t ( l ) = ϕ l ( H t ( l − 1 ) W x h ( l ) + H t − 1 ( l ) W hh ( l ) + b h ( l ) ) H t ( l ) ∈ R n × h ( l ) H_t^{(l)}\in\mathbb{R}^{n\times h^{(l)}} H t ( l ) ∈ R n × h ( l ) l l l W x h ( l ) ∈ R h ( l − 1 ) × h ( l ) W_{xh}^{(l)}\in\mathbb{R}^{h^{(l-1)}\times h^{(l)}} W x h ( l ) ∈ R h ( l − 1 ) × h ( l ) W h h ( l ) ∈ R h ( l ) × h ( l ) W_{hh}^{(l)}\in\mathbb{R}^{h^{(l)}\times h^{(l)}} W hh ( l ) ∈ R h ( l ) × h ( l ) l l l b h ( l ) ∈ R 1 × h ( l ) b_h^{(l)}\in\mathbb{R}^{1\times h^{(l)}} b h ( l ) ∈ R 1 × h ( l ) l l l ϕ l \phi_l ϕ l l l l H t ( 0 ) = X t ∈ R n × D H_t^{(0)}=X_t\in\mathbb{R}^{n\times D} H t ( 0 ) = X t ∈ R n × D H t ( L ) ∈ R n × h ( L ) H_t^{(L)}\in\mathbb{R}^{n\times h^{(L)}} H t ( L ) ∈ R n × h ( L ) L L L O t = H t ( L ) W h q + b q {O}_t={H}_t^{(L)}{W}_{hq}+{b}_q O t = H t ( L ) W h q + b q O t ∈ R n × q O_t\in\mathbb{R}^{n\times q} O t ∈ R n × q W h q ∈ R h ( L ) × q W_{hq}\in\mathbb{R}^{h^{(L)}\times q} W h q ∈ R h ( L ) × q b q ∈ R 1 × q b_q\in\mathbb{R}^{1\times q} b q ∈ R 1 × q
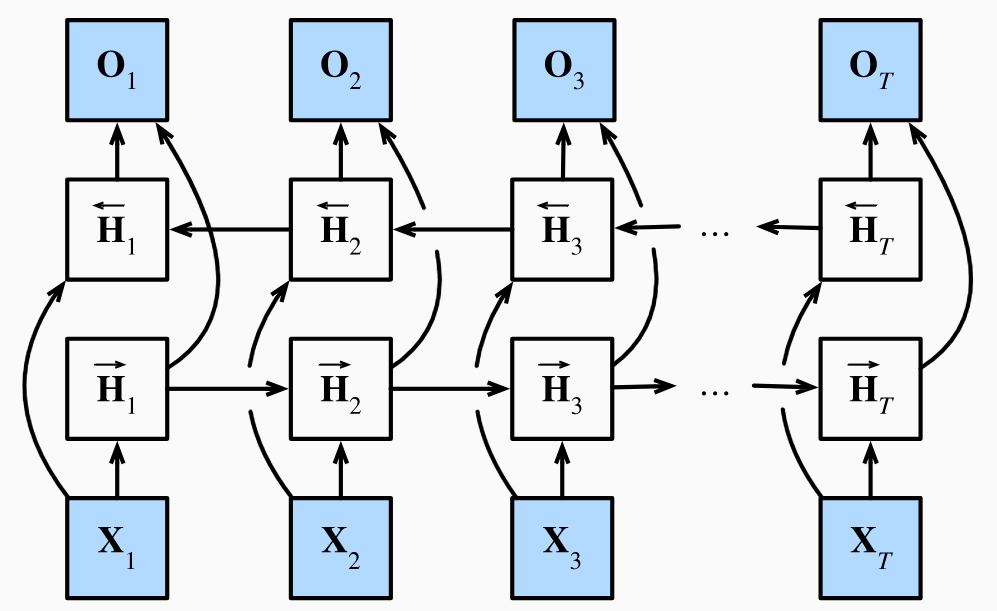
5. 双向循环神经网络
双向循环神经网络的隐藏层输出H t ( f ) ∈ R n × h H_t^{(f)}\in\mathbb{R}^{n\times h} H t ( f ) ∈ R n × h H → t \overrightarrow{H}_t H t H t ( b ) ∈ R n × h H_t^{(b)}\in\mathbb{R}^{n\times h} H t ( b ) ∈ R n × h H ← t \overleftarrow{H}_t H t H → t = ϕ ( X t W x h ( f ) + H → t − 1 W h h ( f ) + b h ( f ) ) H ← t = ϕ ( X t W x h ( b ) + H ← t + 1 W h h ( b ) + b h ( b ) ) \begin{aligned}
\overrightarrow{{H}}_{t}&=\phi({X}_t{W}_{xh}^{(f)}+\overrightarrow{{H}}_{t-1}{W}_{hh}^{(f)}+{b}_h^{(f)})\\
\overleftarrow{{H}}_{t}&=\phi({X}_t{W}_{xh}^{(b)}+\overleftarrow{{H}}_{t+1}{W}_{hh}^{(b)}+{b}_h^{(b)})\end{aligned} H t H t = ϕ ( X t W x h ( f ) + H t − 1 W hh ( f ) + b h ( f ) ) = ϕ ( X t W x h ( b ) + H t + 1 W hh ( b ) + b h ( b ) ) D × h , h × h , 1 × h D\times h,h\times h,1\times h D × h , h × h , 1 × h ϕ \phi ϕ H t ∈ R n × 2 h H_t\in\mathbb{R}^{n\times 2h} H t ∈ R n × 2 h H t = [ H → t , H ← t ] H_t=[\overrightarrow{H}_t,\overleftarrow{H}_t] H t = [ H t , H t ] O t = H t W h q + b q {O}_t={H}_t{W}_{hq}+{b}_q O t = H t W h q + b q O t ∈ R n × q O_t\in\mathbb{R}^{n\times q} O t ∈ R n × q W h q ∈ R 2 h × q W_{hq}\in\mathbb{R}^{2h\times q} W h q ∈ R 2 h × q b q ∈ R 1 × q b_q\in\mathbb{R}^{1\times q} b q ∈ R 1 × q H ← t \overleftarrow{H}_t H t
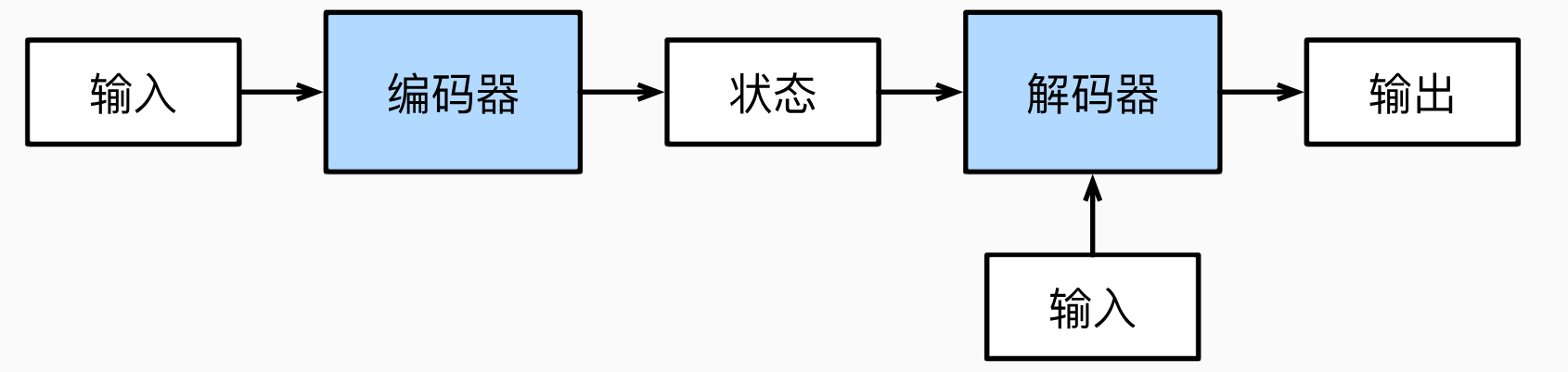
6. 编码器-解码器架构
输入序列 X = x 1 , x 2 , . . . , x T X = {x_1, x_2, ..., x_T} X = x 1 , x 2 , ... , x T x t ∈ R d x_t \in \mathbb{R}^d x t ∈ R d t t t d d d 编码器 将输入序列映射到隐状态序列H = h 1 , h 2 , . . . , h T = Encoder ( X ) H={h_1, h_2, ..., h_T} = \text{Encoder}(X) H = h 1 , h 2 , ... , h T = Encoder ( X ) h t ∈ R h h_t \in \mathbb{R}^h h t ∈ R h t t t 解码器 接收编码器的隐状态(解码器的初始隐状态通常是编码器最后一个时间步的隐状态,也可以是全部隐状态的函数c = q ( h 1 , . . . , h T ) c=q(h_1,...,h_T) c = q ( h 1 , ... , h T ) y 1 , y 2 , . . . , y T ′ {y_1, y_2, ..., y_{T'}} y 1 , y 2 , ... , y T ′ y t ∈ R d y_t \in \mathbb{R}^d y t ∈ R d t t t 输出序列 Y = y 1 , y 2 , . . . , y T ′ = Decoder ( H ) Y = {y_1, y_2, ..., y_{T'}} = \text{Decoder}(H) Y = y 1 , y 2 , ... , y T ′ = Decoder ( H ) T ′ T' T ′ 右侧的输入 指的是解码器在每个时间步接收的前一时间步的输出y t − 1 y_{t-1} y t − 1
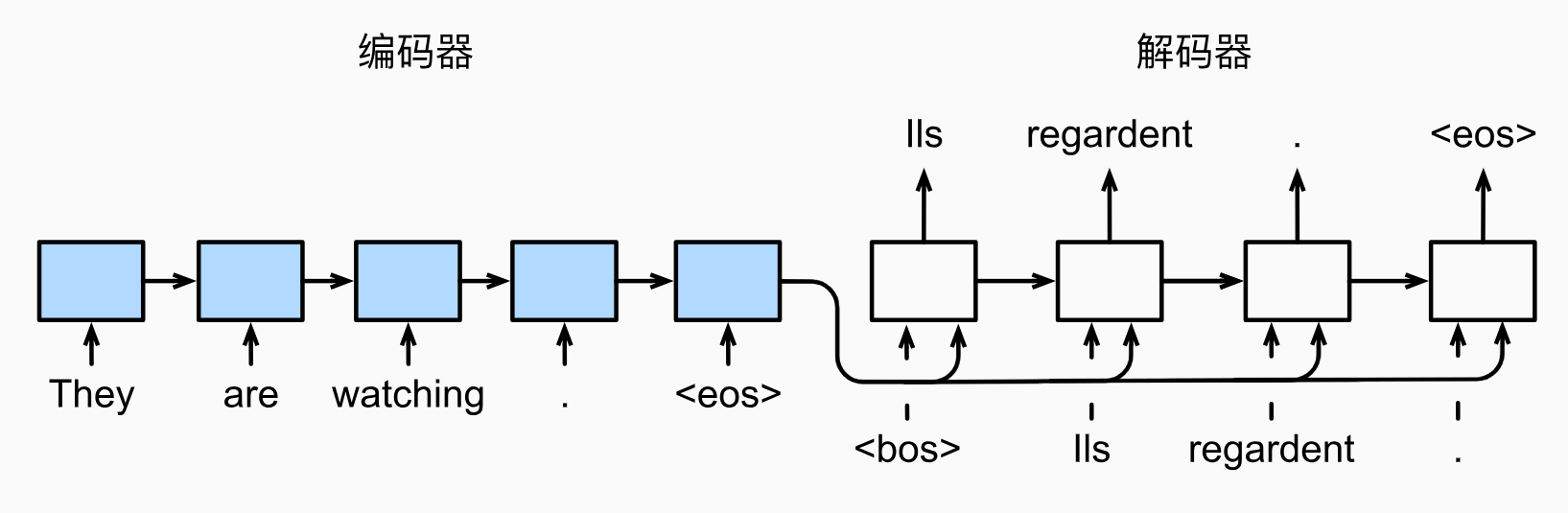
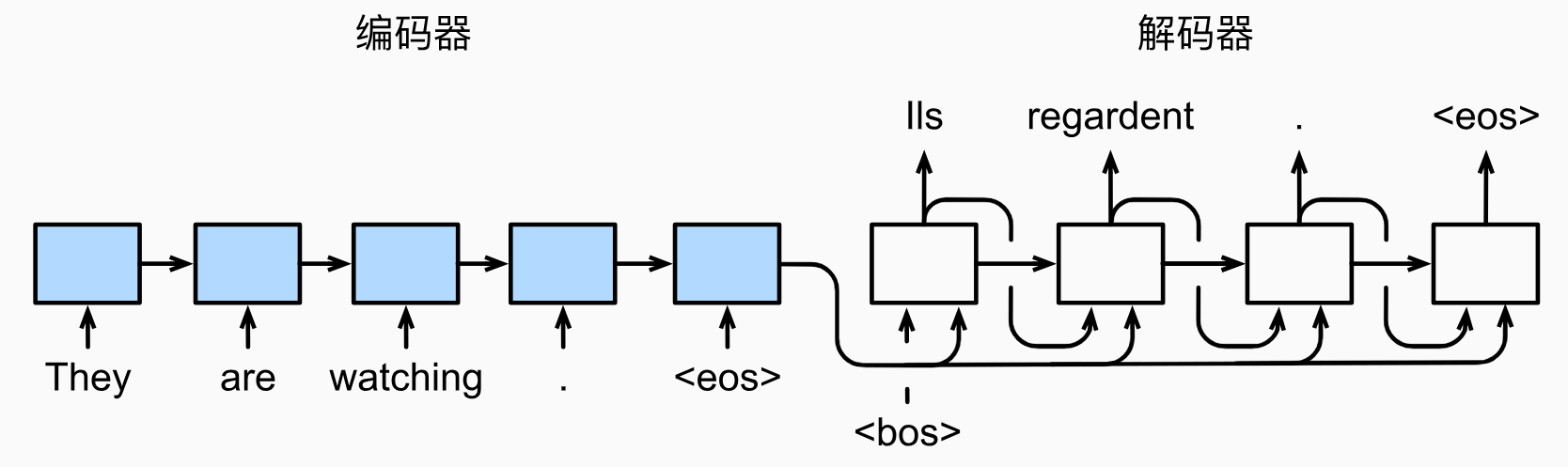
7. seq2seq
eos表示序列结束词元,一旦输出序列生成此词元,模型就会停止预测。
遵循编码器-解码器架构的设计原则,循环神经网络编码器 使用长度可变的序列作为输入,将其转换为固定形状的隐状态 。换言之,输入序列的信息被编码到循环神经网络编码器的隐状态中。解码器 是基于输入序列的编码信息和输出序列已经看见的或者生成的词元来预测下一个词元。可以使用循环神经网络编码器最终的隐状态来初始化 解码器的隐状态,也可以让编码器最终的隐状态在每一个时间步 都作为解码器的输入序列的一部分。
训练时解码器的输入是已知序列(强制教学teacher forcing),而预测时解码器的输入是模型生成的上一步输出。
在预测时,如果每次选择概率最大的词元,那么模型可能会陷入重复 或循环 的输出序列中,并且贪心本来就不能保证概率最大化。为了解决这个问题,可以使用束搜索 beam search,它在每个时间步都会保留k k k
8.4. 注意力机制
分为:
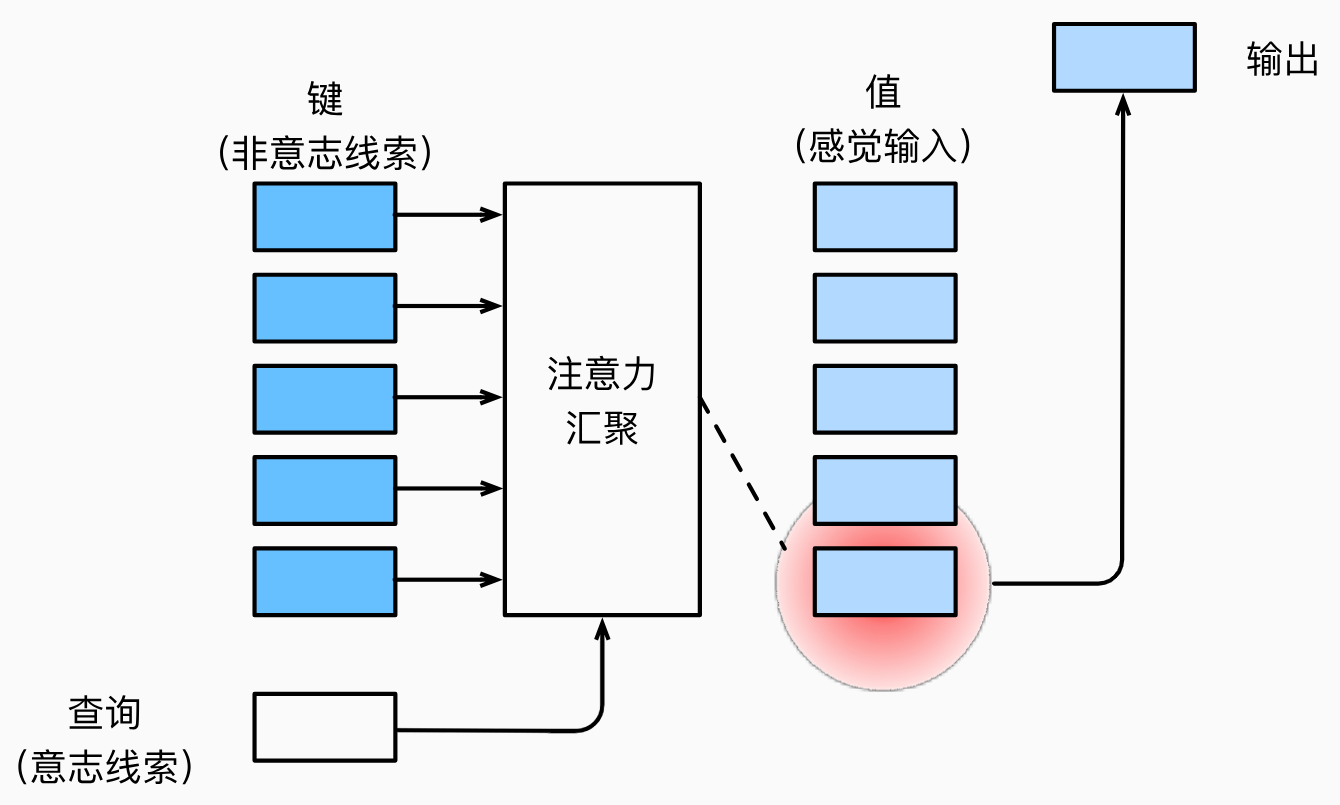
由于突出性的非自主性 提示,如全连接层、汇聚层。
依赖于任务的意志提示,即自主性 提示,这将注意力机制与全连接层或汇聚层区别开来。
自主性提示被称为查询query。给定任何查询,注意力机制通过注意力汇聚attention pooling将选择引导至感官输入sensory inputs(例如中间特征表示)。在注意力机制中,这些感官输入被称为值value。更通俗的解释,每个值都与一个键key配对,这可以想象为感官输入的非自主提示:
1. 非参数注意力汇聚 Nadaraya-Watson核回归
f ( x ) = ∑ i = 1 n K ( x − x i ) ∑ j = 1 n K ( x − x j ) y i = ∑ i = 1 n α ( x , x i ) y i f(x)=\sum_{i=1}^n\frac{K(x-x_i)}{\sum_{j=1}^nK(x-x_j)}y_i=\sum_{i=1}^n\alpha(x,x_i)y_i f ( x ) = i = 1 ∑ n ∑ j = 1 n K ( x − x j ) K ( x − x i ) y i = i = 1 ∑ n α ( x , x i ) y i K K K α \alpha α x x x x i x_i x i x x x ( x i , y i ) (x_i,y_i) ( x i , y i ) x x x y i y_i y i K ( u ) = 1 2 π exp ( − u 2 2 ) K(u)=\frac1{\sqrt{2\pi}}\exp(-\frac{u^2}2) K ( u ) = 2 π 1 exp ( − 2 u 2 ) f ( x ) = ∑ i = 1 n exp ( − ( x − x i ) 2 2 ) ∑ j = 1 n exp ( − ( x − x j ) 2 2 ) y i = ∑ i = 1 n softmax ( − 1 2 ( x − x i ) 2 ) y i \begin{aligned}
f(x)&=\sum_{i=1}^n\frac{\exp(-\frac{(x-x_i)^2}2)}{\sum_{j=1}^n\exp(-\frac{(x-x_j)^2}2)}y_i\\
&=\sum_{i=1}^n\text{softmax}\left(-\frac12(x-x_i)^2\right)y_i\end{aligned} f ( x ) = i = 1 ∑ n ∑ j = 1 n exp ( − 2 ( x − x j ) 2 ) exp ( − 2 ( x − x i ) 2 ) y i = i = 1 ∑ n softmax ( − 2 1 ( x − x i ) 2 ) y i
2. 带参数注意力汇聚
以高斯核为例,带参数的注意力汇聚的计算公式如下:f ( x ) = ∑ i = 1 n softmax ( − 1 2 ( ( x − x i ) w ) 2 ) y i f(x)=\sum_{i=1}^n\text{softmax}\left(-\frac12\left((x-x_i)w\right)^2\right)y_i f ( x ) = i = 1 ∑ n softmax ( − 2 1 ( ( x − x i ) w ) 2 ) y i q , k , v q,k,v q , k , v f ( q ) = ∑ i = 1 n softmax ( − 1 2 ( ( q − k i ) w ) 2 ) v i f(q)=\sum_{i=1}^n\text{softmax}\left(-\frac12\left((q-k_i)w\right)^2\right)v_i f ( q ) = i = 1 ∑ n softmax ( − 2 1 ( ( q − k i ) w ) 2 ) v i
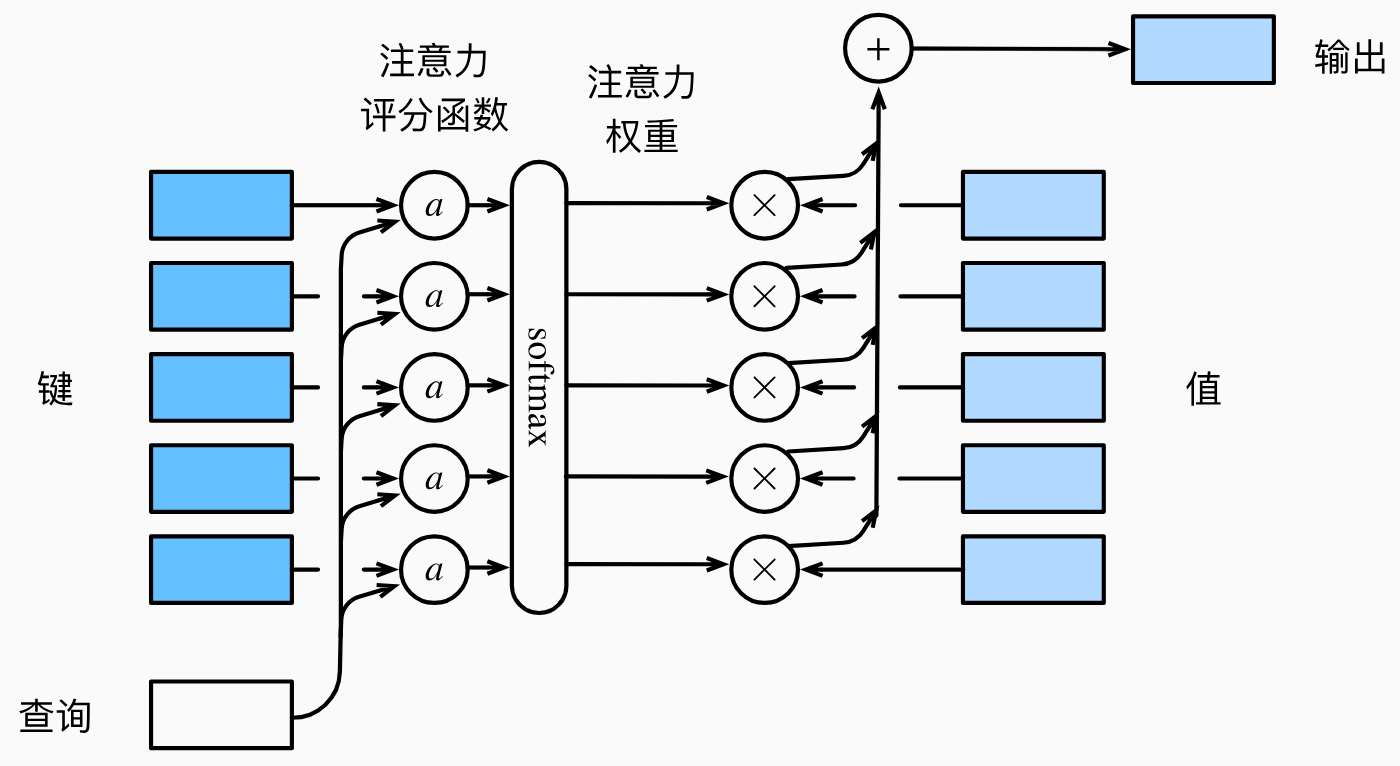
3. 注意力评分函数
注意力评分函数 就是计算查询和键之间的相似度的函数。比如上文的− 1 2 ( ( q − k i ) w ) 2 -\frac12\left((q-k_i)w\right)^2 − 2 1 ( ( q − k i ) w ) 2 a ( q , k ) a(q,k) a ( q , k ) α \alpha α a ( q , k ) a(q,k) a ( q , k ) α ( q , k i ) = softmax ( a ( q , k i ) ) = exp ( a ( q , k i ) ) ∑ j = 1 n exp ( a ( q , k j ) ) \alpha(q,k_i)=\text{softmax}(a(q,k_i))=\frac{\exp(a(q,k_i))}{\sum_{j=1}^n\exp(a(q,k_j))} α ( q , k i ) = softmax ( a ( q , k i )) = ∑ j = 1 n exp ( a ( q , k j )) exp ( a ( q , k i ))
点积评分函数:a ( q , k ) = q ⊤ k a(q,k)=q^\top k a ( q , k ) = q ⊤ k
加性评分函数:a ( q , k ) = v ⊤ tanh ( W q q + W k k ) a(q,k)=v^\top\tanh(W_qq+W_kk) a ( q , k ) = v ⊤ tanh ( W q q + W k k )
缩放点积评分函数:a ( q , k ) = q ⊤ k d a(q,k)=\frac{q^\top k}{\sqrt{d}} a ( q , k ) = d q ⊤ k d d d
给定查询q ∈ R n × d q q\in\mathbb{R}^{n\times d_q} q ∈ R n × d q k ∈ R m × d k k\in\mathbb{R}^{m\times d_k} k ∈ R m × d k v ∈ R m × d v v\in\mathbb{R}^{m\times d_v} v ∈ R m × d v o ∈ R n × d o o\in\mathbb{R}^{n\times d_o} o ∈ R n × d o o = softmax ( q k ⊤ d k ) v o=\text{softmax}\left(\frac{qk^\top}{\sqrt{d_k}}\right)v o = softmax ( d k q k ⊤ ) v h h h o i o_i o i q ∈ R n × d q q\in\mathbb{R}^{n\times d_q} q ∈ R n × d q k ∈ R m × d k k\in\mathbb{R}^{m\times d_k} k ∈ R m × d k v ∈ R m × d v v\in\mathbb{R}^{m\times d_v} v ∈ R m × d v o ∈ R n × h × d o o\in\mathbb{R}^{n\times h\times d_o} o ∈ R n × h × d o o i = softmax ( q W i Q ( k W i K ) ⊤ d k ) W i V o_i=\text{softmax}\left(\frac{qW_i^Q(kW_i^K)^\top}{\sqrt{d_k}}\right)W_i^V o i = softmax ( d k q W i Q ( k W i K ) ⊤ ) W i V W i Q ∈ R d q × d k , W i K ∈ R d q × d k , W i V ∈ R d q × d v W_i^Q\in\mathbb{R}^{d_q\times d_k},W_i^K\in\mathbb{R}^{d_q\times d_k},W_i^V\in\mathbb{R}^{d_q\times d_v} W i Q ∈ R d q × d k , W i K ∈ R d q × d k , W i V ∈ R d q × d v i i i o ∈ R n × h × d o o\in\mathbb{R}^{n\times h\times d_o} o ∈ R n × h × d o h h h
9. 我的一些想法
1. 象形字->embedding
使用汉字的象形字图片转化为其embedding。